Introduction: The AI Revolution and the Enduring Enigma of the Brain
We live in an age of breathtaking artificial intelligence advancements. Large Language Models (LLMs) like ChatGPT, Claude, and Gemini can write poetry, debug code, and converse with startling fluency. The horizon seems bright with the promise (or peril) of Artificial General Intelligence (AGI). Yet, amidst this technological surge, the three-pound marvel inside our skulls – the human brain – continues its quiet reign. It navigates complex social landscapes, generates novel ideas, and adapts to unforeseen circumstances, all while consuming less power than a dim lightbulb, roughly 20 watts[1].
This stark contrast in energy efficiency raises profound questions. How do these systems fundamentally differ in their approach to processing information? Can we quantify intelligence not just by performance, but by the energy required to achieve it? This post explores the intersection of information theory (the math of data), energy conservation (fundamental physics), and time (processing speed) as they relate to intelligence in both humans and AI. We'll delve into a hypothesis: are there fundamental physical limits, dictated by energy, that suggest the human brain's efficiency in synthesizing information might represent a benchmark that current AI paradigms struggle to meet?

The Brain: A Masterclass in Energy-Efficient Information Processing
The brain's computational substrate is biological. Billions of neurons connect via trillions of synapses, communicating through electrochemical signals called action potentials. From an information theory perspective, these firing patterns represent encoded data, processed in a massively parallel fashion. While individual neurons are relatively slow compared to silicon transistors, their sheer number and intricate connectivity allow for incredibly sophisticated computation.
Crucially, evolution has sculpted the brain under the relentless pressure of energy conservation. Every process, from basic perception to abstract thought, must operate within that tight ~20W budget[1]. This constraint likely forced the evolution of incredibly efficient coding schemes, noise-reduction techniques, and hardware specialization. The result? An organ that excels at generalization, learning from sparse data, common-sense reasoning, and creative problem-solving with unparalleled energy economy.
Visualizing Efficiency: MMLU vs. Estimated Energy
To bring these concepts together, we've plotted the MMLU scores against our estimated energy consumption per query for each model, including our human baseline. The goal is to visualize the trade-off between accuracy (higher MMLU) and energy efficiency (lower Joules per query).
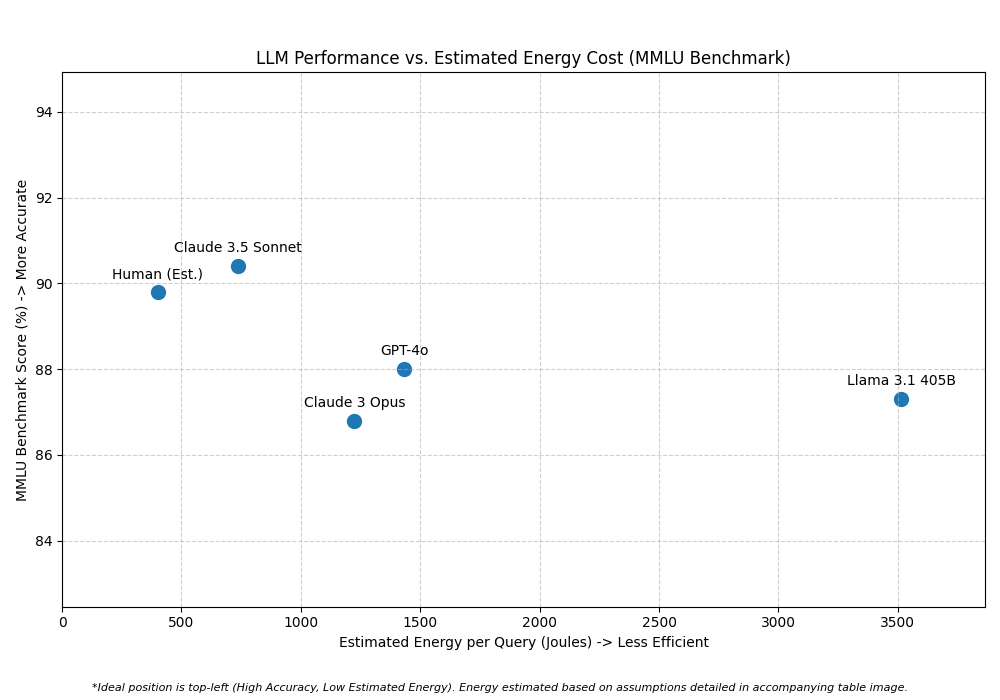
The scatter plot highlights an interesting landscape. While newer models like Claude 3.5 Sonnet achieve very high accuracy, potentially rivaling or exceeding the estimated human expert level on this specific benchmark, their estimated energy cost can be significantly higher. The 'ideal' model would reside in the top-left corner: maximum accuracy with minimum energy expenditure.
The Impact of Inference Time
A crucial factor driving the energy cost difference is the total inference time. This includes both the initial latency (Time To First Token - TTFT) and the time taken to generate the subsequent tokens (throughput). Even if a model has high throughput (many tokens per second), a significant initial latency or a task requiring many tokens means the underlying hardware (GPUs) is drawing power for a longer duration.
Therefore, models that are faster overall (lower latency + higher throughput for the required task) will generally consume less energy for that specific task, assuming similar hardware power draw.
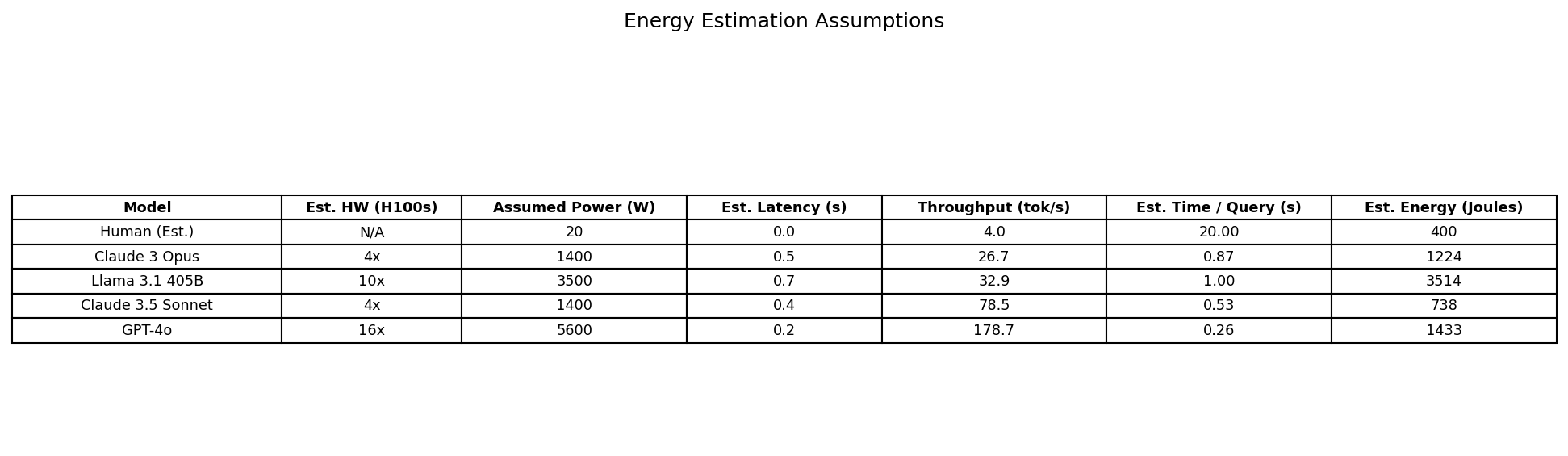
Understanding the Assumptions
It's vital to understand that the energy figures presented are estimates based on several assumptions. Standardized, publicly available energy consumption benchmarks for specific queries on different models are scarce. Therefore, we made the following assumptions to provide a comparative baseline:
- Hardware Configuration: We estimated the number of high-end GPUs (like NVIDIA H100s) required to run each model efficiently, based loosely on parameter counts and known architectures. Larger models generally require more GPUs.
- Power Draw: We assumed the GPUs operate at a significant fraction (50%) of their Thermal Design Power (TDP) during inference, plus any base system power. Actual power draw varies greatly depending on the workload.
- Task Definition: We standardized the 'task' as processing a single MMLU-like query requiring an estimated latency period plus the generation of 10 tokens. The human baseline used an estimated average task completion time.
These assumptions allow for relative comparison but absolute energy values will differ based on real-world hardware, software optimizations, and specific query complexity. The goal is to illustrate the magnitude of potential energy differences.
Large Language Models: Power-Hungry Titans of Text
Modern LLMs are built on architectures like the Transformer, which uses mechanisms like "attention" to weigh the importance of different words (tokens) in a sequence. They learn by ingesting colossal datasets – often a significant portion of the internet – adjusting billions, sometimes trillions, of parameters (weights) to predict the next token in a sequence.
This process is incredibly power-intensive. Training OpenAI's GPT-3 model (175 billion parameters), for instance, consumed an estimated 1,287 Megawatt-hours (MWh) of electricity[2] – equivalent to the annual energy consumption of over 120 US homes. Even running inference – using the trained model to answer a prompt or generate text – demands significant energy, far exceeding the brain's instantaneous power draw for completing a comparable cognitive task[3]. While individual inferences are less energy-intensive than the massive one-off training cost, the cumulative energy consumption for deploying these models at scale for millions of users quickly becomes enormous. Though LLMs achieve superhuman performance on many language benchmarks, this capability comes at a staggering energetic cost, highlighting a fundamental difference in efficiency compared to biological intelligence.

Connecting the Dots: Information, Energy, and the Physics of Computation
Can physics help us understand these differences? Information theory, pioneered by Claude Shannon, provides tools to quantify information (using bits) and understand the limits of communication channels (channel capacity). It tells us about the amount and rate at which information can be processed or transmitted.
Crucially, Rolf Landauer established a fundamental link between information and thermodynamics with his principle: erasing one bit of information necessarily dissipates a minimum amount of energy into the environment as heat (kT ln 2 Joules, where k is Boltzmann's constant and T is the absolute temperature)[4]. This applies to logically irreversible operations, common in standard computer architectures.
While this theoretical minimum is tiny for a single bit erasure at room temperature, performing billions or trillions of such operations per second, as modern processors do, means the fundamental energy cost associated with computation itself cannot be ignored, especially at scale.
Synthesizing new, complex, and accurate information – the hallmark of intelligence – isn't just about retrieving stored data; it involves computation, error correction, and overcoming uncertainty. These processes are thermodynamically costly. Generating information with higher complexity, greater accuracy, or at a faster rate inherently demands more energy expenditure to distinguish signal from noise and structure from randomness.
The Hypothesis: Is Brain-Level Efficiency the Benchmark?
If we accept the brain's linguistic input/output largely stems from neuronal activity constrained by its ~20W energy budget[1], and assume it's a highly optimized system shaped by evolution, then current LLM architectures, even if scaled to consume only 20W, are unlikely to significantly surpass the general information synthesis capabilities (considering complexity, accuracy, and rate combined) of the human brain's language centers.
Comparing Throughput Efficiency: Tokens per Watt-Hour
Let's simplify the efficiency comparison to look directly at the rate of output versus the power cost. We can calculate this as Tokens per Watt-Hour (Tokens/Wh), derived purely from the model's estimated continuous Throughput (tokens/second) and its Power Draw (Watts) during operation.
This metric ignores latency and specific task structures, focusing solely on how many tokens are generated for each watt-hour of energy consumed, assuming continuous generation.
Here's how the models compare using this direct throughput efficiency metric:
| Entity | Throughput (tok/s) | Est. Power (W) | Efficiency (Tokens/Wh) |
|---|---|---|---|
| Human (Est.) | ~4 | ~20 | ~720 |
| Claude 3 Opus | ~50.2 | ~1400 | ~129 |
| Llama 3.1 405B | ~42.8 | ~3500 | ~44 |
| Claude 3.5 Sonnet | ~150.1 | ~1400 | ~386 |
| GPT-4o | ~150.1 | ~5600 | ~97 |
In this direct comparison, Claude 3.5 Sonnet shows the highest throughput efficiency among the LLMs (~386 Tokens/Wh), benefiting from its high token rate relative to its estimated power consumption. GPT-4o, despite similar throughput, is less efficient due to its significantly higher power draw. Llama 3.1 405B shows the lowest efficiency, penalized by both its lower throughput and high power needs in this estimation.
Crucially, even the most efficient LLM in this calculation (Sonnet) operates at roughly half the estimated Tokens/Wh efficiency of the human baseline (386 vs 720). This reinforces the core point: achieving biological levels of energy efficiency for information processing remains a major hurdle for current AI hardware and architectures, even when focusing purely on output rate versus power.
Implications, Challenges, and the Future
If this hypothesis holds weight, what does it mean for AI's future? It suggests a potential need to shift focus beyond simply scaling current models. We might need:
- More Efficient Architectures: Research into algorithms that require fundamentally less computation or energy per unit of "intelligent" output.
- Novel Hardware: Exploration of brain-inspired hardware, like neuromorphic chips, designed for low-power, parallel processing.
- Better Metrics: Developing ways to quantify "intelligence efficiency" – perhaps Joules per accurately synthesized concept or similar – to benchmark progress beyond raw task performance.
Of course, this view has limitations. The brain isn't necessarily perfectly optimal in an engineering sense. Future breakthroughs, perhaps in quantum computing or entirely new AI paradigms, could rewrite the rules. Current LLMs might also become significantly more energy-efficient through software and hardware optimization. Furthermore, precisely modeling the brain's information processing and energy use remains a monumental scientific challenge.
Conclusion: Towards Sustainable Intelligence
The dazzling capabilities of modern AI can sometimes obscure the fundamental physical constraints under which intelligence operates. Energy, information, and time are inextricably linked. The human brain, operating within a strict power budget, stands as a remarkable testament to energy-efficient information synthesis.
While current LLMs achieve incredible feats, their energy demands highlight a potential divergence from the path of biological intelligence. Considering the energetic cost isn't just an environmental concern; it might hint at fundamental limits or necessary paradigm shifts required to achieve truly general and sustainable artificial intelligence. The quest isn't just for smarter AI, but perhaps for wiser AI, capable of profound insight without burning out our planet or its power grids.
References
- Raichle, M. E., & Gusnard, D. A. (2002). Appraising the brain's energy budget. Proceedings of the National Academy of Sciences, 99(16), 10237-10239. (Also see BrainFacts.org summary: How Much Energy Does the Brain Use?)
- Patterson, D., et al. (2021). Carbon emissions and large neural network training. arXiv preprint arXiv:2104.10350. (Figure often cited, e.g., AdASci.org)
- Luccioni, A. S., Viguier, S., & Ligozat, A. L. (2022). Estimating the Carbon Footprint of BLOOM, a 176B Parameter Language Model. arXiv preprint arXiv:2211.02001. (Discusses inference vs training costs, general point supported by various analyses).
- Landauer, R. (1961). Irreversibility and heat generation in the computing process. IBM Journal of Research and Development, 5(3), 183-191. (See also Bennett, C. H. (2003). Notes on Landauer's principle, reversible computation, and Maxwell's Demon. Studies in History and Philosophy of Science Part B: Studies in History and Philosophy of Modern Physics, 34(3), 501-510.)
- OpenAI. (2023). GPT-4 Technical Report. arXiv preprint arXiv:2303.08774. (OpenAI GPT-4 Research Page)
- International Energy Agency (IEA) / Electric Power Research Institute (EPRI) estimates suggest ~2.9 Wh per standard query. Example reporting: Euronews, Goldman Sachs Insights.
- Wei, J., Wang, X., Schuurmans, D., Bosma, M., Chi, E., Le, Q., & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35, 24824-24837.
- CoT energy multiplier is an estimate based on increased token generation and computational steps inherent in the method. Precise figures vary based on model, task complexity, and CoT verbosity. See discussions on concise CoT, e.g., Yao et al. (2024) arXiv:2401.05618.