Language models have come a long way. From decoding steps along a Viterbi trellis in the early days of speech recognition, to RNNs and LSTMs shaping our first major leaps in sequence modeling, to modern Transformers and GPT-based architectures—each generation has marked a pivotal shift in how we train computers to understand and generate human language.
This journey isn't just a story of academic breakthroughs; it's a tale of computational creativity, engineering ingenuity, and the relentless pursuit of making machines truly conversational. Along the way, we've witnessed not just improvements in model quality, but fundamental changes in training methodologies, serving infrastructure, and the very way we think about language processing.
The Evolutionary Timeline
Statistical Foundations
The earliest language models were built on statistical foundations. Hidden Markov Models (HMMs) and the famous Viterbi algorithm laid the groundwork for understanding sequences. These models were primarily used in speech recognition, where the goal was to find the most likely sequence of words given an acoustic signal.
Key Innovation: Viterbi Decoding
The Viterbi algorithm efficiently finds the most probable path through a trellis of states, enabling real-time speech recognition and marking the beginning of practical language processing systems.
Neural Network Renaissance
The introduction of Recurrent Neural Networks (RNNs) marked a significant departure from purely statistical approaches. RNNs could theoretically model sequences of arbitrary length, but in practice struggled with long-term dependencies due to vanishing gradient problems.
Key Innovation: LSTM Architecture
Long Short-Term Memory (LSTM) networks solved the vanishing gradient problem through gating mechanisms, enabling models to maintain information over much longer sequences and revolutionizing sequence modeling.
The Transformer Revolution
The publication of "Attention Is All You Need" in 2017 fundamentally changed language modeling. Transformers introduced the self-attention mechanism, allowing models to directly connect information across arbitrary distances in a sequence, leading to dramatic improvements in both training efficiency and model quality.
Key Innovation: Self-Attention Mechanism
Self-attention allows models to weigh the importance of different parts of the input simultaneously, enabling parallelizable training and capturing complex linguistic relationships that RNNs struggled with.
Technical Evolution: From Sequential to Parallel
RNN Limitations
RNNs process sequences step-by-step, making parallel training impossible. Each hidden state depends on the previous one, creating a computational bottleneck that limited both training speed and the ability to capture long-range dependencies effectively.
Transformer Breakthrough
Transformers eliminated the sequential constraint by using self-attention to directly model relationships between all positions simultaneously. This parallelization dramatically reduced training time and improved the model's ability to capture complex patterns.
Architecture Evolution
Comparing Model Architectures
RNN/LSTM Era
- Sequential processing
- Limited parallelization
- Vanishing gradient issues
- Difficulty with long sequences
- Simple attention mechanisms
Transformer Era
- Parallel processing
- Highly parallelizable training
- Self-attention mechanisms
- Excellent long-range modeling
- Scalable to massive datasets
Modern Optimizations
- Efficient attention variants
- Mixed precision training
- Model parallelism
- Advanced optimization
- Specialized hardware
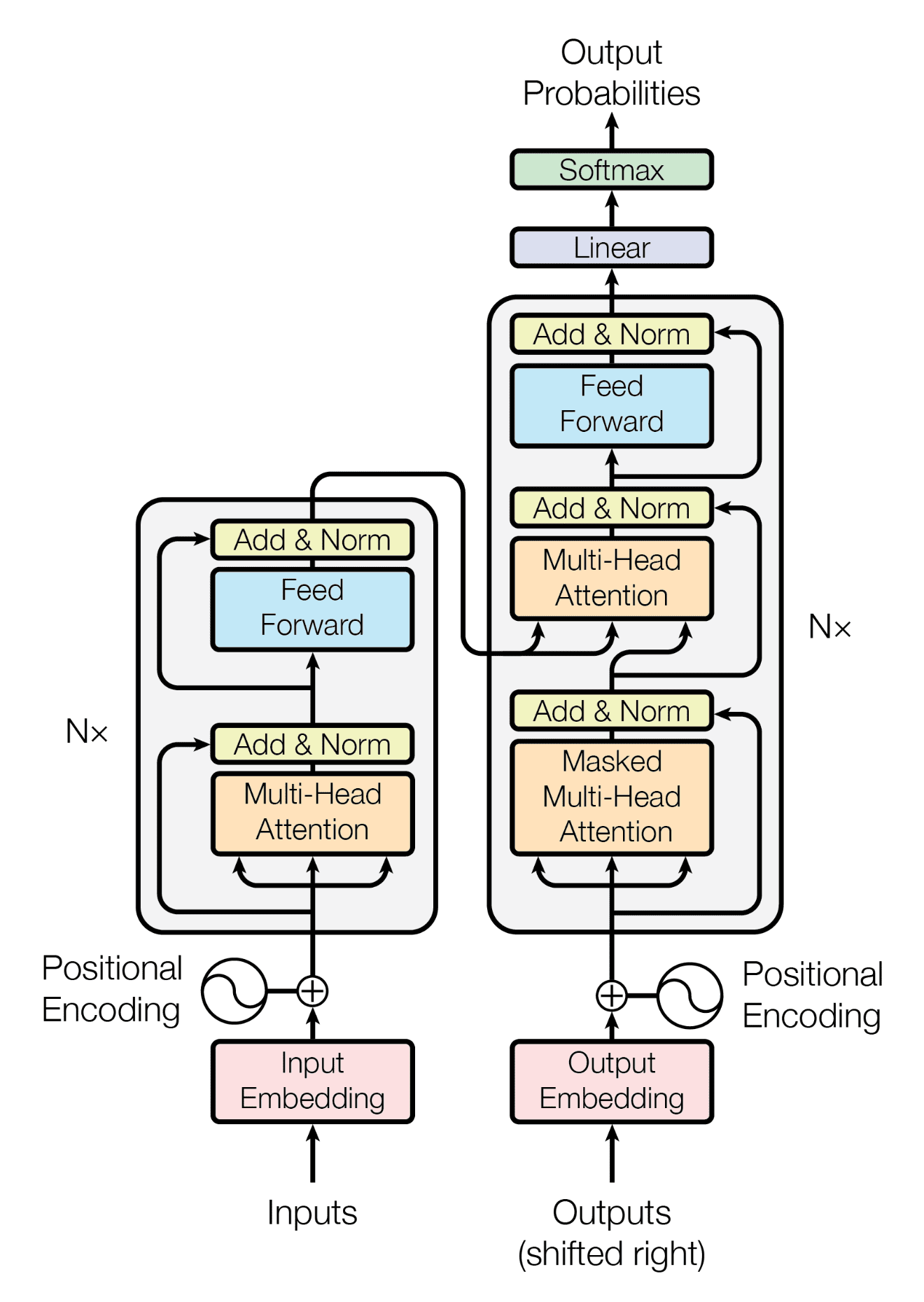
The rise of the Transformer wasn't just about better performance—it enabled a new paradigm of scaling. Unlike RNNs, where increasing sequence length led to exponentially longer training times, Transformers could efficiently process much longer contexts. This scalability, combined with the explosion of available computational resources and data, paved the way for the large language models we see today.
Training methodologies evolved in parallel. While early language models were trained from scratch on relatively small datasets, modern approaches leverage massive unsupervised pre-training followed by task-specific fine-tuning. This paradigm shift has made it possible to create general-purpose language models that can be adapted to a wide variety of downstream tasks.
Looking Forward: The Next Wave
Efficiency Innovations
Future models will likely focus on efficiency through sparse attention patterns, mixture-of-experts architectures, and novel training techniques that maintain quality while reducing computational costs.
Specialized Architectures
We can expect domain-specific models tailored for medicine, law, education, and other specialized fields, moving beyond general-purpose language models to expert systems.
Multimodal Integration
The future lies in models that seamlessly integrate text, images, audio, and other modalities, creating more comprehensive and capable AI systems.
Looking ahead, we can expect even larger or more efficient models tailored to specific verticals (medicine, law, education). Sparse gating and other efficiency-focused architectures may allow us to keep scaling while avoiding the ballooning costs of training and serving fully dense models. Meanwhile, open-source communities continue to chip away at the traditionally massive computational barriers, democratizing access to powerful language AI.
The evolution from Viterbi algorithms to GPT represents more than just technological progress—it reflects our growing understanding of language itself. Each breakthrough has brought us closer to models that not only process language but truly understand context, nuance, and meaning in ways that were unimaginable just a few decades ago.
Sources
- Vaswani, A., Shazeer, N., Parmar, N., et al. "Attention Is All You Need" arXiv preprint arXiv:1706.03762 (2017).
- Hochreiter, S., & Schmidhuber, J. "Long Short-Term Memory" Neural Computation 9, no. 8 (1997): 1735-1780.
- Viterbi, A. "Error bounds for convolutional codes and an asymptotically optimum decoding algorithm" IEEE Transactions on Information Theory 13, no. 2 (1967): 260-269.
- Radford, A., Wu, J., Child, R., et al. "Language Models are Unsupervised Multitask Learners" OpenAI blog (2019).
- Brown, T., Mann, B., Ryder, N., et al. "Language Models are Few-Shot Learners" arXiv preprint arXiv:2005.14165 (2020).